Price 1.0
From Evolution and Games
(→Intro) |
|||
| Line 1: | Line 1: | ||
[[Category:Price equation]] | [[Category:Price equation]] | ||
| + | |||
| + | [[Price | Go to the front-page of Price equation tutorials ]] | ||
== A very simple model == | == A very simple model == | ||
Revision as of 22:39, 18 September 2010
Go to the front-page of Price equation tutorials
Contents |
A very simple model
Suppose that we have a population of 2 individuals. We depart from a population in which individual no 1 has "the" gene, while the other, individual no 2, does not. In Price equation terms, that means that the variable qi, which denotes the frequency of the gene in individual i becomes: q1 = 1, q2 = 0.
The next generation of 2 individuals is drawn in a very simple way. First we draw the first, and then we draw the second. That makes it - for those who care - a Wright-Fisher process. At both draws the new individual could be the offspring of individual no 1 or of individual no 2. Reproduction is asexual, hence the offspring is a perfect copy of its parent. Now here comes the important thing. We assume that at both draws, the probability of no 1 from the parent population -- the one with the gene -- to be drawn for reproduction is p, while the probability of no 2 from the parent population -- the one without the gene -- to be drawn for reproduction is 1 − p. That gives us four possible transitions.

What the new generation will be is a random variable. What the current generation is, is not; the current generation is simply given. We can however think of a hypothetical chance experiment such that, in combination with the actual random transition, we get two random variables, between which we can define a covariance. So here is the recipe.
1) Draw one of the individuals from the parent population (this is the hypothetical random variable).
2) Draw the next generation (this is the actual random thing that happens in the the transition).
The random variable X is now defined as the genotype of the parent. That is a simple, albeit hypothetical random variable:
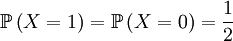 .
.
Then we define the random variable Y, which is the number of offspring that the parent that has been drawn begets. This is a slightly more complicated random variable, because the chances depend on which of the two the (candidate) parent is. So we get a (not too long) list of conditional probabilities. Worth working through!
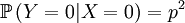
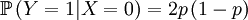
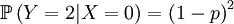
The other conditional probabilities are the reverse,because the parent of a new individual is the one if it is not the other, and vice versa...
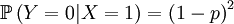
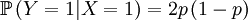
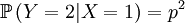
The X and Y are pretty well defined, so we can also compute the covariance of these two actual random variables...
Let us first look at expectations...
![{E}\left[ X\right]=\frac{1}{2}](/wiki/images/math/5/3/c/53ca4d829ebdfac56b0a4a795b3fdb6b.png)
![\mathbb{E}\left[ X\right] =\sum_{x=0,1}x\mathbb{P}\left( X=x\right) =\mathbb{P}\left( X=1\right) =\frac{1}{2}](/wiki/images/math/2/c/4/2c401f701d21b6b828ae3df887a7c269.png)
For obvious symmetry reasons; the total number of offspring is 2, and either one could be the parent, so ...
![\mathbb{E}\left[ Y\right] =1](/wiki/images/math/f/6/8/f6851309af9717e71df00c1227f0d760.png)
![\mathbb{E}\left[ Y\right] =\sum_{x=0,1}\sum_{y=0,1,2}y\mathbb{P}\left( X=x,Y=y\right) =](/wiki/images/math/f/7/4/f74d9e52b468ce85048f50db01ed34ea.png)
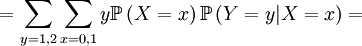
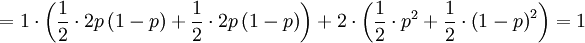
And ...
![\mathbb{E}\left[ XY\right] = p](/wiki/images/math/0/b/0/0b0cae3e6fa6d5a915323e22d6dc0e86.png)
![\mathbb{E}\left[ XY\right] =\sum_{x=0,1}\sum_{y=0,1,2}xy\mathbb{P}\left( X=x,Y=y\right)](/wiki/images/math/d/0/5/d0544224643e3e37b045d33c37858acf.png)

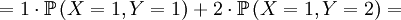
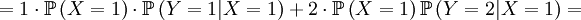
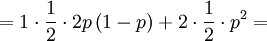
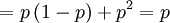
The covariance is then...
![Cov\left( X,Y\right) =\mathbb{E}\left[ XY\right] -\mathbb{E}\left[ X\right]
\mathbb{E}\left[ Y\right] =p-\frac{1}{2}\cdot 1=p-\frac{1}{2}](/wiki/images/math/9/5/9/95972491d6444efd4a65da33c0d6b4bc.png)
The Price equation for this very simple model
An interesting question would be: is it good to have the gene?
Or, if we do statistics: suppose we know that the process has this form, but we don't know the value of p. Then the question becomes: is p>1/2, or, equivalently, is Cov( X,Y) >0. Below we will try to answer that question. But first we will look at what the Price equation does to all of this.
For a given transition, the Price equation constitutes an identity. The frequency of the gene in the parent population is, in general, defined as
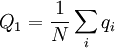
where N is the number of individuals, and qi is the frequency of the gene in individual i (For this particular model this quantity is 0.5).
The frequency of the gene in the offspring population is
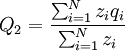
where zi is the number of times individual i in the parent population was drawn for reproduction. The Price equation 1.0 then is the following identity:
![\triangle Q=Q_{2}-Q_{1}=\frac{N}{\sum_{i}z_{i}}\left[ \frac{\sum_{i}z_{i}q_{i}}{N}-\left( \frac{\sum_{i}z_{i}}{N}\right) \left( \frac{\sum_{i}q_{i}}{N}\right) \right]](/wiki/images/math/4/4/f/44f8e6f5c4948ff8a33f39ac612ebe80.png)
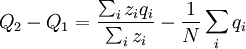
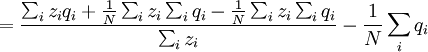
![=N\left[ \frac{\frac{1}{N}\sum_{i}z_{i}q_{i}-\left( \frac{1}{N}\sum_{i}z_{i}\right) \left( \frac{1}{N}\sum_{i}q_{i}\right) }{\sum_{i}z_{i}}\right]](/wiki/images/math/7/2/5/72542d3492ab16325a77c4dc68060bb9.png)
![=\frac{N}{\sum_{i}z_{i}}\left[ \frac{\sum_{i}z_{i}q_{i}}{N}-\left( \frac{\sum_{i}z_{i}}{N}\right) \left( \frac{\sum_{i}q_{i}}{N}\right) \right]](/wiki/images/math/9/5/1/9519ee3f6ad0f358a7a00ccce05fcd78.png)
In this simple case for N = 2 this amounts to
![\triangle Q=\left[ \frac{\sum_{i}z_{i}q_{i}}{2}-\frac{\sum_{i}q_{i}}{2}\right]](/wiki/images/math/c/a/5/ca5d82021f0f9888efe52c553365e922.png)
Confusion
The point where confusion starts, is that George Price named the right hand side of this equation Cov(z,q). The claim of the Price equation - which we contend - is that the equation unveils that a change in frequency - 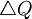 - is explained by the covariance between having the gene and the number of offspring - Cov(z,q). The central issue here is that this Cov(z,q) is discussed as if it were a real covariance. Is that correct?
- is explained by the covariance between having the gene and the number of offspring - Cov(z,q). The central issue here is that this Cov(z,q) is discussed as if it were a real covariance. Is that correct?
Try yourself!
If you tried a few times, you may have found out that can attain different values; the next generation is a random draw, which implies that the frequency Q can go up by 1/2, remain what it is, or go down by 1/2. The value of this so-called Covariance just follows that change in frequency (and because it is not a real covariance, we will use quotation marks from now on). This creates an illusion of understanding, because whatever happens, the covariance changes along with the outcome of the chance experiment. In other words: the data explain the data.
This is, of course, not OK; the true and well-defined covariance is
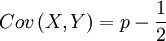
This does not depend on the realisation. Cov(X,Y) defines the properties of the chance experiment, and the realisation of this chance experiment defines "Cov(z,q)".
What would a proper probability theorist do?
Try to figure out the transition probabilities for the suggested model. It seems that you are a proper probability theorist, because that is what you just did. Congrats!
What would a proper statistician do?
If you are interested in statistics, which is only natural if you care for evolution, and you do not know the true model that generates the transitions, then you would want to try to answer the question what $p$ is. Is p>1/2? Then having the gene is good for reproduction. Is p<1/2? Then not.
Is p=1/2? Then it is good nor bad. So how do we find out? Well, the thing with statistics is that you will never find out for sure. All we can do is try to find ways to estimate this p, or design tests on if and how p differs from 1/2, that will help us make statements about the true model with some confidence. Here are a few such statements.
Estimation of p
One of the reasons that so many are convinced of the value of the Price equation is that it almost hits the nail on the head (even though it misses the head completely). So here we go with what sometimes feels as an indication that the Price equation is not so wrong after all. If you sense this in yourself, just return to the interactive part above.
If you draw a new generation, then that new generation comes with a "Cov(z,q)" . With probability p2 you draw two 1's, which implies "Cov(z,q)"=+1/2. With probability (1 − p)2 you draw two 0's, which implies "Cov(z,q)"=-1/2. So"Cov(z,q)" is actually a random variable itself, the characteristics of which we can look at. Two natural characteristics are its expected value and its variance. Now the expectation of this so-called variance is, luckily,
![\mathbb{E}\left[ ^{\prime \prime }Cov\left( z,q\right) ^{\prime \prime }\right] =p-\frac{1}{2}.](/wiki/images/math/a/4/6/a46e71f039e6452777617b45badd591f.png)
![\mathbb{E}\left[ ^{\prime \prime }Cov\left( z,q\right) ^{\prime \prime }\right] =\mathbb{E}\left[ \frac{\sum_{i}z_{i}q_{i}}{2}-\frac{\sum_{i}q_{i} }{2}\right] =](/wiki/images/math/1/8/7/1873d7b9fdc9ed7d41931b372a3bf56e.png)
![=\sum_{z_{1}=0,1,2}\left[ \frac{z_{1}q_{1}}{2}-\frac{q_{1}}{2}\right]
\mathbb{P}\left( Z_{1}=z_{1}\right) =](/wiki/images/math/9/0/b/90b8e9c1a40bb323d567dceefc503c46.png)
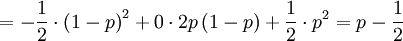
Unfortunately, the realisation varies quite a bit, as we have seen in interactive part above. This is reflected in the variance of "Cov(z,q)";
![Var\left[ ^{\prime \prime }Cov\left( z,q\right) ^{\prime \prime }\right] = \frac{1}{2}p\left( 1-p\right)](/wiki/images/math/1/1/1/1114b82f0daa51745b8d14838082f5be.png)
![Var\left[ ^{\prime \prime }Cov\left( z,q\right) ^{\prime \prime }\right] =\mathbb{E}\left[ \left( ^{\prime \prime }Cov\left( z,q\right) ^{\prime
\prime }\right) ^{2}\right] -\mathbb{E}^{2}\left[ \left( ^{\prime \prime}Cov\left( z,q\right) ^{\prime \prime }\right) \right] =\frac{1}{2}p\left( 1-p\right)](/wiki/images/math/7/d/7/7d77bf328039188706ac8e9541d60f02.png)
This variance can be reduced though if we take a large sample. Suppose that we have individuals i=1,...,n with the gene, and individuals i=n+1,...,2n
without it. Now we draw the next generation in the same way as before, which looks a bit more general; 2n individuals are drawn, and at every draw
individual i has a probability with which it is drawn to reproduce. For i=1,...,n this probability is 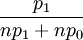 .
.
For i=n+1,...,2n this probability is 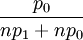 . For this transition, one can show that
. For this transition, one can show that
![\mathbb{E}\left[ \frac{\sum_{i=1}^{2n}z_{i}q_{i}}{2n}-\frac{\sum_{i=1}^{2n}q_{i}}{2n}\right] =p-\frac{1}{2}](/wiki/images/math/8/4/6/846d1d33e40389dba07d74a9fe37608b.png)
and
![\lim_{n\rightarrow \infty }Var\left[ \frac{\sum_{i=1}^{2n}z_{i}q_{i}}{2n}-\frac{\sum_{i=1}^{2n}q_{i}}{2n}\right] =0](/wiki/images/math/5/6/a/56a99afd15899e8793eb40197eae68d0.png)
If we indeed define
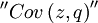 as
as 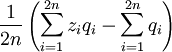
then
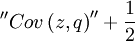
is an unbiased estimator of p - because
![\mathbb{E}\left[ ^{\prime \prime }Cov\left( z,q\right) ^{\prime \prime }\right] =p-\frac{1}{2}](/wiki/images/math/e/8/0/e8048a7a26147c65fb621084b1151ac8.png) .
.
The quantity is also regularly referred to as the sample covariance, which is not the true covariance (true covariance = fixed property of two random variables, sample covariance = itself a random variable).
Testing properties of p
The sample covariance is typically also used as input for in tests of the type:
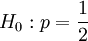
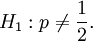
So how does the Price equation help here?
Not. For determining the properties of the model, the Price equation did not help, and in fact cannot even be of use. We found the transition probabilities just by doing probability calculations. For doing statistics the Price equation did not help either. And yes, the Price equation applied to one actual draw does have the sample covariance of that draw in it, and the sample covariance is a useful thing, but we do not need the Price equation for knowing that the sample covariance is useful. The sample covariance has been around forever; it was there well before George Price was born, and it is used in parameter estmation and hypothesis testing in all other fields of science, where no one has ever heard of G.R. Price. And, most importantly, using the sample covariance is obviously not the same as using the Price equation. It is using the sample covariance.
