Repeated Games
From Evolution and Games
This project studies the evolution of cooperation in a repeated prisoner's dilemma with discounting. A version of the paper can be downloaded here
Contents |
Run the simulations
You can download the software here. Once the program is running just click on the big play button to start the fun. Feel free to re-arrange and re-size the windows, zoom-in and out as the program is running. Click here if you need more information about running this program.
The simulation program
What are strategies?
Strategies are either programmed explicitly as finite automata, as regular expressions, or as Turing machines. The set of regular expressions is equivalent to the set of finite automata, but because they are represented differently, the likelihoods of mutations also are different; a mutation that is a single step in one representation requires a series of steps in the other and vice versa.
A finite automaton is a list of states, and for every state it prescribes what the automaton plays when in that state, to which state it goes if the opponent plays cooperate, and to which state it goes if the opponent plays defect.

The computer representation of the automate above is an array with the following values:
[C, 0, 1 | D, 1, 1]
Each array position represents a state. Every state codes for an action and two indexes, where to go on cooperation, and where to go on defection. The first state (indexed 0) codes the action for the empty game history. Go to Computer representation of strategies for repeated games to see more details and more ways to represent strategies.
The simulation
There are N individuals and every generation they are randomly matched in pairs to play the repeated game. The repeated game has a probability of breakdown smaller than 1, hence the number of repetitions is a random variable. The payoffs from the interactions are used in the update step. There are two options; the Moran process and the Wright-Fisher process. In the Moran process, in every generation one individual is chosen to be replaced, and one is chosen to replace. All individuals are equally likely to be chosen to be replaced. Probabilities of being chosen to replace are proportional to fitness. In the Wright-Fisher process all individuals in the new generations are drawn one by one, and independently, from a distribution where, again, the probability of being the offspring of individual j from the old generation is proportional to the payoff of j. The Moran process is extremely inefficient, so we always use the Wright-Fisher process, but the option is there.
After the new generation has been drawn, all individuals have a small and independent probability with which they mutate. There are four types of mutations; mutations that add a state, mutations that delete a state, mutations that change the output when in a state, and mutations that change for a given state to which state this player goes, given an action of the opponent. This completes the cycle for a generation. The cycle is repeated a large number of times.

Mutations
Possible mutations are adding (randomly constructed) states , deleting states (if the array has more than one state), and reassigning destination states at random. On deleting a state the transitions are rewired to the remaining states. The following video shows an example path of mutations:
Measures of cooperativeness and reciprocity
(See the formal and longer version of this section here)
There are two reasons why we would like to have measures for cooperativeness and reciprocity. The first and most important reason is obvious; we would simply like to know how cooperative, and how reciprocal, strategies are during a run. The second reason is that these measures may serve as an indication of indirect invasions. Typically an indirect invasion is characterized by a change in reciprocity followed by a change in cooperativeness.
Any measure of cooperativeness will have to weigh the different histories, and as we will see, every choice how to weigh them has appealing properties and drawbacks. In contrast to the definitions earlier, here it is more natural to look at histories that only reflect what actions the other player has played. This captures all relevant histories for the measurement of cooperativeness, because what a strategy S itself has played is uniquely determined by the history of actions by the other player. We propose measures of reciprocity and cooperation that are more formally described here.
An intuition for what this measure does can be gained from the following figures. The top bar represents the empty history. The second bar represents histories of length 1, and is split in two; the history where the other has cooperated, and the one where the other has defected. The third bar represents histories of lenth 2, and is split in four; the histories CC, CD, DC and DD. This continues indefinitely, but for the pictures we restrict ourselves to histories of length 5 or less. If a part is blue, then that means that the strategy reacts to this history with cooperation, if it is red, then the strategy reacts with defection. Cooperativeness weighs the blueness of those pictures.
 Always Cooperate |
 |
 Always Defect |
 |
 Condition on first move |
 |
 Grim Trigger |
|
 Negative Handshake (DTFT) |
 |
 Tit for Tat |
 |
 Tat for Tit |
 |
 Tit for two Tats |
 |
 Win stay lose shift |
 |
A measure for reciprocity can be constructed by comparing how much the cooperativeness of strategy S is changed if its opponent plays D rather than C. In the figure above, this is visualized as the difference in blueness below two neighbouring bits that share their history up to the one before last period.
See in more detail how the measures are defined.
Analyzing the simulation output
Population states are classified by ranking the composing strategies from frequent to infrequent. Then we look at the minimum number of strategies that is needed to capture at least a fixed percentage of the population. As a default, we choose 90% for the threshold. A population state is then characterized by its dimensionality (pure, 2 strategies, 3 strategies, more than 3 strategies) and the actual most popular strategy, resp. the 2 most popular and the 3 most popular strategies, as they are ranked. If 3 strategies are not enough to capture this fixed percentage of the population, then we think of the population as being lost in the interior, or in the dark zone. With mutation rates that are not too high, the population hardly ever gets into the dark zone.
The software first reduces a simulation run by registring transitions from area to area, as pictured blow (pictures), and thereby it reduces the simulation run to a sequence of areas in which the population finds itself. At every transition, the software then determines if this is a transition that is advantageous, disadvantageous or neutral. Going from area A (where strategy A accounts for more than 90% of the population) to AB (where strategy A accounts for less, and A and B together count for more than 90% of the population, and A is most and B is second most popular) is for instance a neutral transition if A and B are neutral mutants, advantageous if B dominates A and disadvantageous if B dominates A.
If a matrix game with strategies than A and B would result in a coordination game, then this transition is also classified as disadvantageous, as the replicator dynamics would point towards pure A and not away from it. If this matrix game would only have a mixed equilibrium, then the transition is classified as advantageous, as the replicator dynamics would point away from pure A. This more or less ignores that the fraction of A in the actual equilibrium mixture might be more than 90%.
As explained in the paper, this is unavoidable, but if we want data invasions of which we can actually analyse, it is also an argument to choose high thresholds. (High thresholds come with large dark zones, so if we want to avoid the simulation run to (temporarily) get lost in the dark zone, they will have to go together with low mutation probabilities). The harm done is expected to be limited though. The results indicate that if we restrict the game to A and B, then all mixed equilibria are prone to fixation out of a mixture anyway, even if the equilibrium mixture is 50-50. Equilibria that are close to the boundary are enormously more prone to a fixation event, because not only are they close to the brorder already, but the dynamics are also weaker, the closer to the equilibrium. Therefore we do not expect that it happens a lot that we classify a population as A, while it really is spending a considerable amount of time in an equilibrium mixture of more than 90% A an less than 10% B - and ever less so the higher the threshold.
Within this sequence of areas, we can classify states as...
The best responder
In order to be able to determine if a finite automaton - and hence a pure strategy - is a Nash equilibrium, we have constructed a small routine in the program called the best responder. This routine finds the payoff of the best response against strategy S, as well as a best response. If the payoff of S against itself equals this payoff, then S is a Nash equilibrium. This is a useful device, since the infinity of the strategy space does not allow us to simply compare the payoff of S against itself to the payoff of all other strategies against S one after the other.
Suppose strategy S is an automaton with K states. Any state k is characterized by an action played by S when it finds itself in this state, and a list of transitions as a function of the action played by the opponent of S. With a slightly abusive notation - S is a function of histories elsewhere, while here it is easier to make it a function of states - we will write the first as
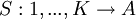
and the latter as
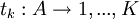 , k = 1,...,K.
, k = 1,...,K.
The value of being in state k is denoted by V(k). We aim to find a solution to the following system:
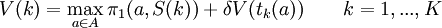
Let 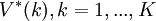 be the solution to this system. The discounted value in the initial state,
be the solution to this system. The discounted value in the initial state, 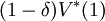 , is the maximal discounted payoff to be earned against S, and
, is the maximal discounted payoff to be earned against S, and 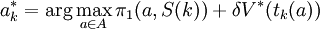 gives the optimal action when S is in state k.
gives the optimal action when S is in state k.
The best responder does the following iteration.
Initialisation step:

Iteration step:
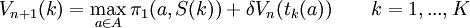
It is quite straightforward that this iteration converges, as is shown in the following simple lemma. We will assume that the initialisation makes sure that we begin with values for all states that are below the solution of the system (whenever this procedure is invoked, we make sure that is in fact the case) but that is not actually necessary for convergence.
Lemma Iffor all k and if
then the above iteration converges to
.
Proof First, iffor all k, then also
for all k. Hence
for all states k and all iterations n. By definition we also have
for all k Therefore
for all k This implies that
and since δ < 0 we find that
for all k. QED.
The best responder gives us both the maximum payoff when playing against S, and an optimal strategy when playing against S, as 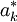 prescribes what to play when S is in state k. For numerical reasons, we actually use the latter. It is important for us to determine whether or not the payoff of S against itself is exactly equal to the maximum payoff when playing against S. The iteration with which the best responder finds the latter can have a numerical inaccuracy in it, and the evaluating the payoff of two given strategies against each other (here: S against S) can too. These are however different inaccuracies, so in order to have the same inaccuracies in both, we use the strategy that the best responder gives, first let it play that against S, then let S play against itself, and compare the two payoffs. If they are equal, then S is a best response
to itself.
prescribes what to play when S is in state k. For numerical reasons, we actually use the latter. It is important for us to determine whether or not the payoff of S against itself is exactly equal to the maximum payoff when playing against S. The iteration with which the best responder finds the latter can have a numerical inaccuracy in it, and the evaluating the payoff of two given strategies against each other (here: S against S) can too. These are however different inaccuracies, so in order to have the same inaccuracies in both, we use the strategy that the best responder gives, first let it play that against S, then let S play against itself, and compare the two payoffs. If they are equal, then S is a best response
to itself.
Note that the computer program works with phenotypes, not with genotypes, so two different ways to encode for instance the strategy AllD will be treated as one and the same strategy.
